7.5 The Normal Distribution
Carl Friedrich Gauss invented the normal distribution, perhaps the most important distribution in statistics. Here is a technical definition: a continuous random variable has a normal distribution with mean and standard deviation if the p.d.f. is
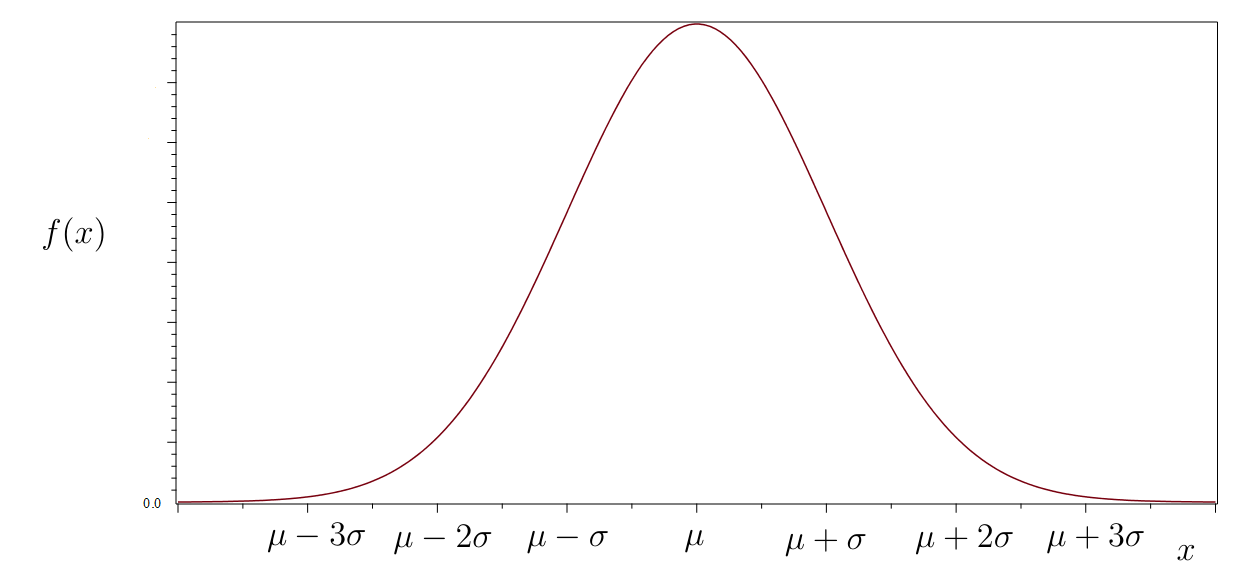
Figure 7.10 gives a plot of the distribution.
Things to know:
-
1.
Our shorthand for “ is normally distributed with mean and standard deviation ” will be So, for example, means is normally distributed with mean and standard deviation
-
2.
The distribution is symmetric and bell-shaped, and is centered at the mean Thus, the mean locates the center of the distribution. The standard deviation controls the spread of the distribution. The location and spread are illustrated in Figure 7.11.
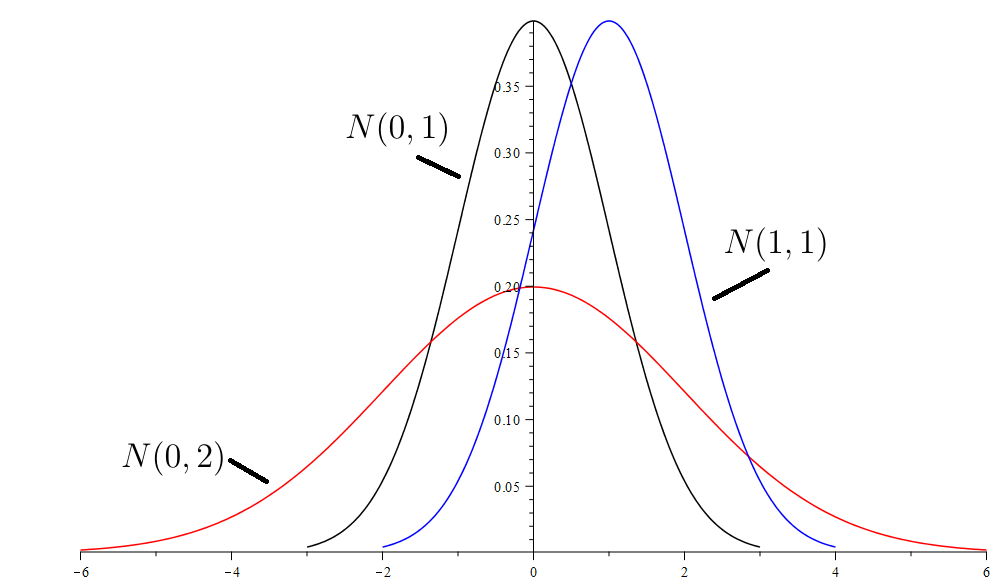
Figure 7.11: Different Normal Distributions -
3.
The graph of has exactly two inflection points. They are located horizontally at and respectively.
-
4.
If then
Other then a few very special cases, it is not possible to compute exact areas under a normal distribution, making approximation techniques necessary. For our purposes, Excel has two built-in commands for working with a normal distribution that we will use frequently. They are covered in the next to sections.
7.5.1 Excel’s NORM.DIST
The Excel command NORM.DIST approximates areas for a normal distribution. Given and any real number then
It’s vital to recognize that the command gives the area to the left of , as illustrated below.
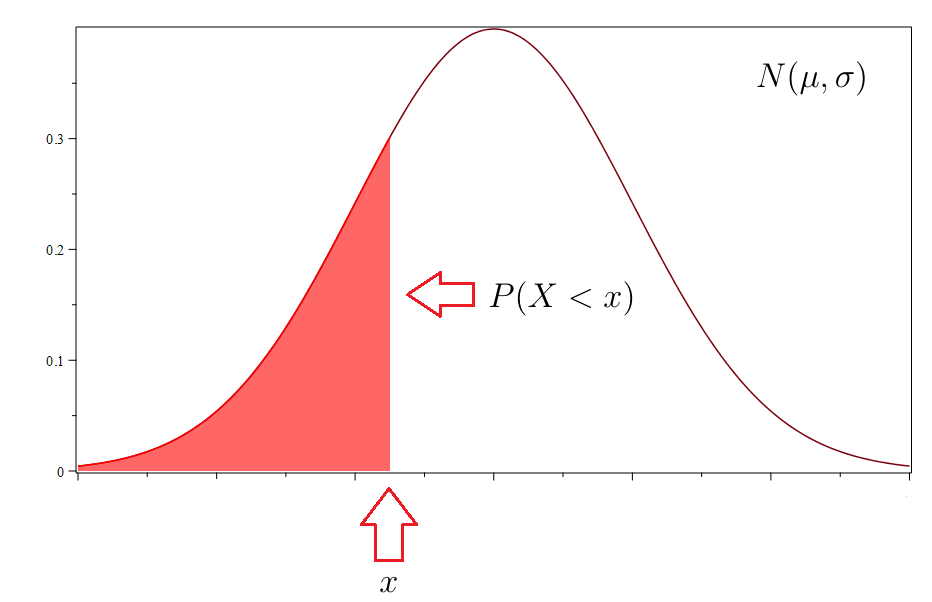
This means that if and if you want to approximate using NORM.DIST, you must subtract the result of the command from 1, that is,
Similarly, if and are real numbers with then
and so
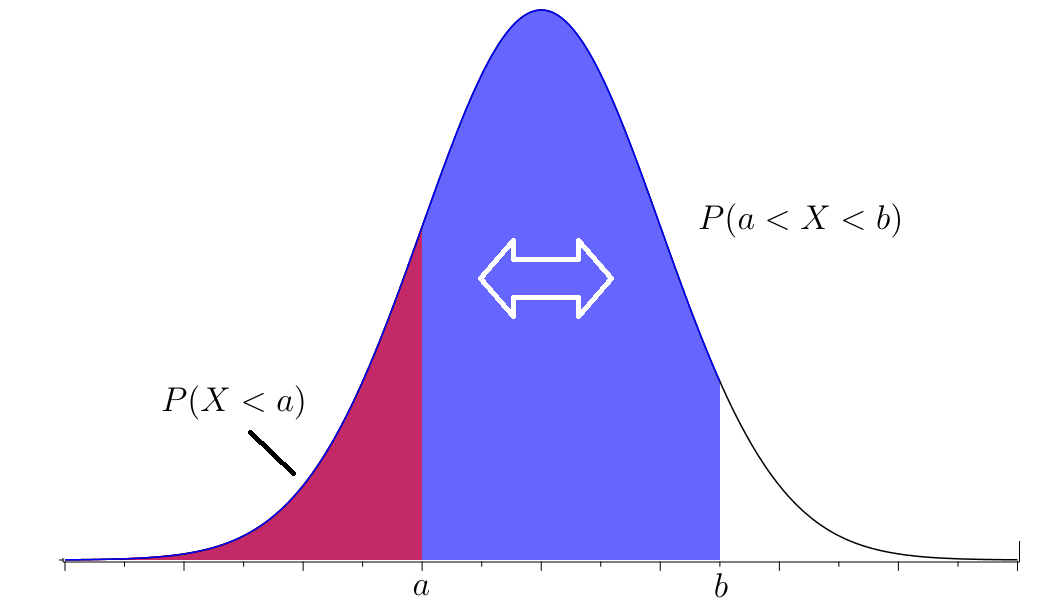
These computations are illustrated in the next example.
Example 7.5.1.
Suppose that so that is normally distributed with mean and standard deviation A graph of the distribution is given below.
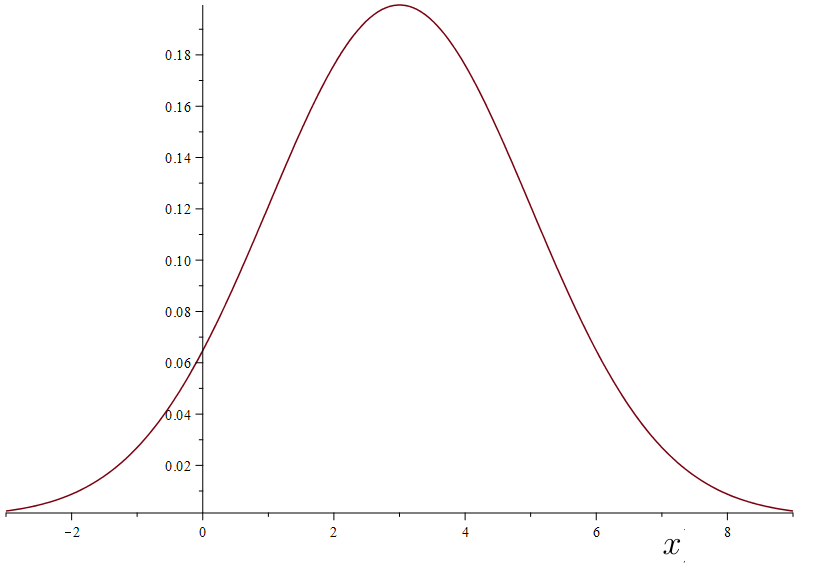
Some probability calculations in Excel:
-
1.
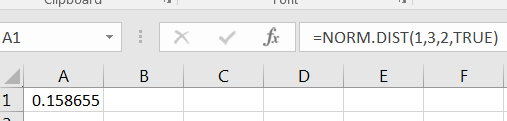
Figure 7.15: Area to the Left of 1 -
2.
Figure 7.16: Area to the Right of 1 -
3.
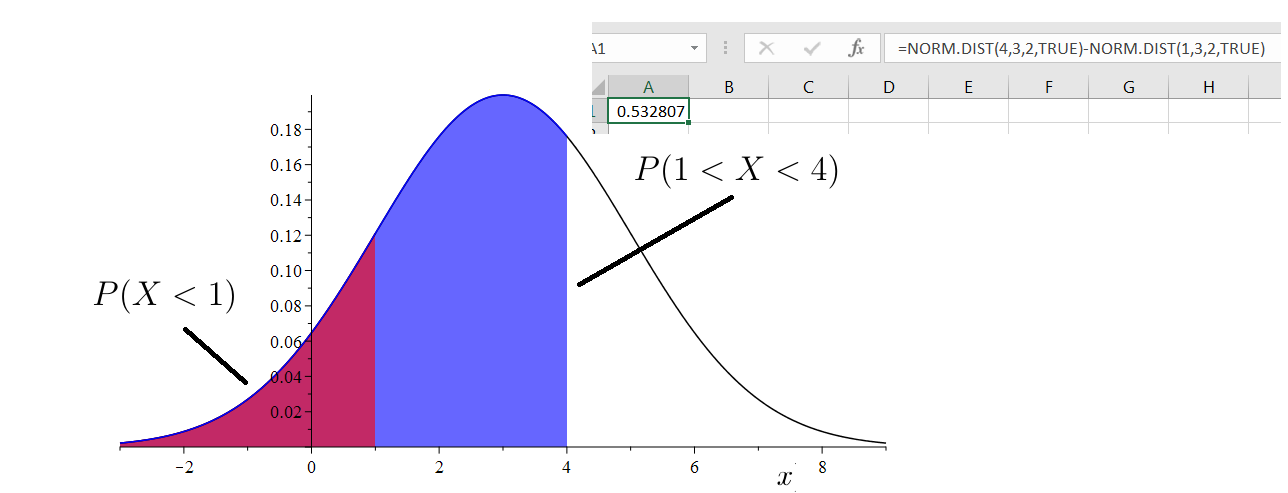
Figure 7.17: Area between 1 and 4
7.5.2 Excel’s NORM.INV
Excel’s NORM.INV reverses the process of NORM.DIST. That is, where NORM.DIST computes an area to the left of a given value of the command NORM.INV computes a value for for given area to the left. Suppose that and suppose that you want to find the value such that for some desired area . Then
In other words, NORM.INV computes percentile scores of normal distributions. Following are some example computations.
Example 7.5.2.
Suppose again that
-
1.
The value where is
Thus, the 80th percentile of is approximately 4.683242467.
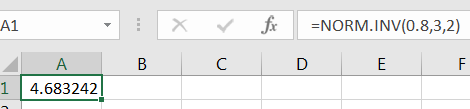
Figure 7.18: 80th Percentile of -
2.
If we apply NORM.DIST to the prior result, we’ll get 0.8, demonstrating the relationship between NORM.DIST and NORM.INV.
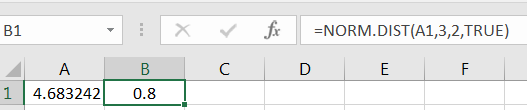
Figure 7.19: NORM.DIST and NORM.INV are Inverse Functions
7.5.3 The Standard Normal Distribution
The normal distribution with mean 0 and standard deviation 1 is called the standard normal distribution. For the standard normal distribution, it is customary to use the letter for the distribution, so is the shorthand notation. The standard normal distribution is displayed in Figure 7.11.
Suppose that It is a theorem of calculus that the random variable
has a standard normal distribution,3030Recall that if a population has mean and standard deviation then gives the number of standard deviations is from i.e.,
Moreover, for any two real numbers and with from calculus it can be shown that
| (7.5) |
Equation (7.5) allows for computing areas for any normal distribution by computing areas using only the standard normal, which is of computational significance if one doesn’t have access to command like NORM.DIST or NORM.INV. The following example illustrates.
Example 7.5.3.
Suppose again that Note that the value is 0.5 standard deviations above the mean. This means that the area to the left of 4 in is the same as the areas to the left of 0.5 in See Figure 7.20.

7.5.4 The 68 - 95 - 99.7 “Rule”
Suppose that is a random variable with mean and standard deviation Recall that the phrase “ is within standard deviations of the mean” means that satisfies the inequality
or that is in the interval Knowing
for various values of provides information on the behavior of the random variable
Suppose that and let be a positive integer. Equation (7.5) gives that the probability a randomly generated is within standard deviations of the mean is the same as the probability that a randomly generate number from a standard normal distribution is within the interval That is,
So, for a normally distributed population the proportion of that falls within 1 standard deviation of the mean is
In words, for a normally distributed population, about 68.3% of all values fall within 1 standard deviation of the mean.
Similarly, again for the proportion that fall within 2 standard deviations of the mean is
Thus, for a normally distributed population, about 95% of all values fall within 2 standard deviations of the mean.
The reader should check that for a normally distributed population, the percent that fall within 3 standard deviations of the mean is about 99.7%. Combining these results is typically called the “The 68 - 95 - 99.7 Rule.” The choice of word “rule” is unfortunate, as this isn’t a rule, but instead is a theorem. Theorems are not arbitrary diktats, but instead are true statements backed by rigorous proofs. This text isn’t concerned with rigorous mathematical proofs, but know that they exist.
A word of caution on the 68 - 95 - 99.7 rule: this holds for normally distributed populations. If you are working with a population that has a different distribution, then these percents a likely different.
7.5.5 Central Limit Theorem
We now discuss one of the most important theorems in statistics, which ultimately in the punchline of the prior chapter. Recall that whether looking at sample means or sample proportions, their distributions were roughly bell-shaped and symmetric, centered at the mean of the population from which the samples were taken. Moreover, as the sample size increased, the spread of the sample means and sample proportions shrunk. This behavior can be proved, and is known as the Central Limit Theorem (CLT).
Theorem (The Central Limit Theorem). Suppose that a large population has mean and finite standard deviation For random samples of size if is sufficiently large, then the distribution for will be approximately normal, with the mean approximately and standard deviation approximately In symbols, One can also write and
Remarks:
-
•
If the population then for any sample size i.e., if is normal, is always normal with mean and standard deviation
-
•
If is “pathological,” large sample sizes may be necessary to see bell-shaped distributions for For our purposes, we will use as a rule-of-thumb for sufficiently large.
-
•
Note that the standard deviation of gets smaller as gets larger.
Example 7.5.4.
Suppose population has mean and standard deviation Suppose a random sample size is drawn from the population. Estimate 3131In words, if a random sample of size 30 is drawn from a population with mean 4 and standard deviation 7, what is the probability that the sample mean is greater than 5.
Solution: Since we can use CLT. Now and Since the distribution of is approximately normal, using Excel we have
When working with proportions, the CLT still applies, but the notation is changed a bit.
Corollary Suppose that a large population contains a proportion of things of Type A. For random samples of size if is sufficiently large, then the distribution of sample proportions of things of Type A will be approximately normal, with the mean approximately and standard deviation approximately In symbols, One can also write and
Remark:
-
•
If population is “pathological,” large sample sizes may be necessary to see bell-shaped distributions for For our purposes, we will use and as a rule-of-thumb for sufficiently large.
Example 7.5.5.
Suppose a population contains things of Type A. Suppose a random sample size is drawn from the population. Estimate 3232In words, if a random sample of size 100 is drawn from a population with what is the probability that the sample proportion is smaller than 0.25.
Solution: Since and we can use CLT. Now using Excel we have
7.5.6 CLT Simulation - Optional
In the prior chapter, we saw several demonstrations that sample means and sample proportions have approximately bell-shaped distributions centered at the population mean or proportion, respectively. Let’s do that again, while checking on the mean and standard deviation of sample statistics.
The simulation will be sharpest if we make the population normal, so let us use
The sample size doesn’t matter, so we’ll use here. Thus, in this simulation, we will have
| (7.6) |
Use Excel to simulate taking 1,000 samples of size 10 from

We’ll compare the observed behavior of the sample means to (7.6). For each sample, compute and then create a frequency histogram for the 1,000 sample means. You’ll get a histogram that looks similar to Figure 7.22.

Note the bell shape, and that the mean of the ’s appears to be about 5. Compute the sample mean and sample standard deviation of the sample means, as in Figure 7.23.

Your sample mean of the sample means will be close to 5. Moreover, your sample standard deviation of the sample means will be near to
Lastly, compute the percent of ’s that fall within 1, 2 and 3 standard deviations of the mean. You’ll get results that are very close to the 68-95-99.7 rule for normal populations. First compute the bounds of the three intervals about the mean of the sample means, as in Figure 7.24.

Then count the number of ’s that fall to the left of the lower and upper bounds of the intervals, as in Figure 7.25.

Now the percents can be computed directly, as in Figure 7.26. The results will give further evidence that the sample means have a normal distribution.

7.5.7 Exercises
-
1.
Suppose that Find the mean and standard deviation of compute and and sketch each probability.
-
2.
Compute and Sketch each probability.
-
3.
Suppose that Compute the first and third quartiles of
-
4.
For a certain standardized exam, scores are normally distributed with a mean of 100 and standard deviation of 10. What exam score is needed to be above the 90th percentile?
-
5.
Compute such that Sketch a picture that illustrates.
-
6.
Suppose population has mean 6 and standard deviation 10. A random sample of size 100 is drawn from Estimate
-
7.
Suppose population has mean 8 and standard deviation 4. A random sample of size 40 is drawn from Estimate
-
8.
A random sample of size 8 is drawn from Compute
-
9.
At a large school, 65% of students participate in athletics. A random sample of 200 students is drawn. What is the probability that the observed sample percentage of athletes is greater than 70%?
-
10.
A fair 6-sided die is rolled 300 times, and the proportion of 1’s observed is recorded. Approximate the probability that the proportion of observed 1’s exceeds 0.2.
-
11.
Suppose that and suppose that a random sample of size 50 is drawn from Compare the values of and
-
12.
(Optional) Let We know that and it turns out that Use a simulation to study the behavior of for samples of size 50. Compare the results to the CLT.