10.4 Z-Test on a Single Population Mean
This section will develop the Z-Test on a Single Population Mean (or simply -Test), which was partially illustrated in Section 10.2. This test is appropriate if and only if one can reasonably assume that the population of sample means are normally distributed (or approximately normally distributed).
Suppose that represents a large population of numbers with unknown mean and standard deviation Suppose that we are going to take a simple random sample of size from and then use that sample to do a -Test on When can we assume that the population of sample means will be normally distributed, or approximately normally distributed?
-
•
If is normally distributed, then the population of sample means will be exactly normally distributed with mean and standard deviation
-
•
If is not normally distributed, but the sample size is sufficiently large, then by the Central Limit Theorem, the population of sample means will be approximately normally distributed with mean and standard deviation The rule-of-thumb for “sufficiently large” we’ll us is but 30 might not be large enough if the population is too pathological.
In symbols, if either assumptions are met, then
Bottom-line on using a -Test: In order use a -Test, must be known, and the population must be normal or the sample size sufficiently large. If is unknown, do not use a -Test.
10.4.1 The Test Statistic and -value
If we can assume that
then the random variable
| (10.2) |
will have a standard normal distribution, i.e., The random variable is used for the test statistic in a -Test.
Recall that the -value is the chance of observing the test statistic, or anything more extreme, assuming is true. The -value depends on these three parts: (1) the value of the test statistic, (2) the direction of extreme, and (3)
We’ll examine the -value computation in each of the three different setups for
If is true, then Remember that the population mean is a fixed value. If then the larger is, the stronger the evidence the observed sample mean, is against that is, the weakest evidence provides against occurs when Since we don’t want to reject unless there is strong evidence to do so, we assume in computing the -value. This maximizes the value of the computed -value, thus holding the observed evidence to the strongest standard in deciding whether to reject
Bottom line: In computing the -value, in assuming is true, we assume the
To compute the -value then, we use in Equation (10.2):
The observed value of is used to compute the corresponding observed test statistic, as given below:
| (10.3) |
Using to Compute a -value
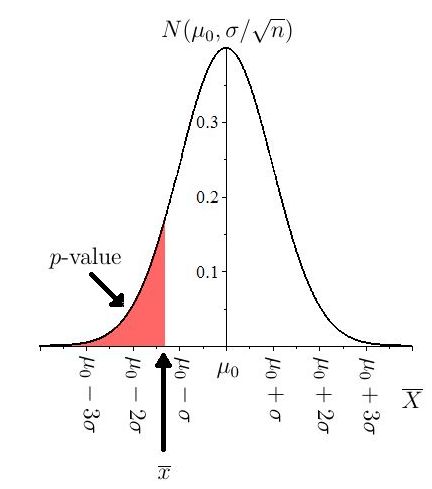
There are two ways we can compute the -value. The first method uses the observed sample mean In this case, the -value is the chance of observing or anything more extreme(smaller), assuming is true (). If then the -value is
This is shown graphically in Figure 10.5.
Example 10.4.1.
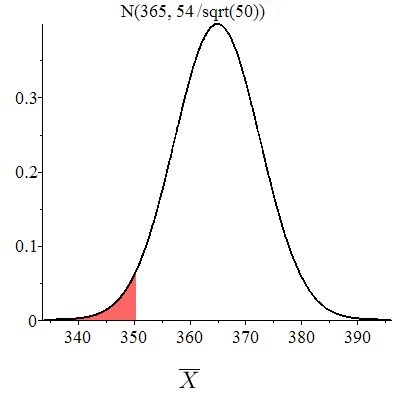
A company advertises that their product will last at least 1 year before breaking, but a consumer protection agency suspects fraud. To test this, the agency took a random sample of size 50 of the product, and the average number of days until failure was 350.4 with a sample standard deviation of 54.1. At the significance level of 5%, test whether the company is guilty of fraud. For mysterious reasons, it is known that the population standard deviation is
Solution: Recall from Example 10.3.1 on page 10.3.1 that is the claim that Since the sample size of is at least 30, the distribution for the sample means is approximately Now the observed sample mean is so the -value is
The -value is shown in Figure 10.6.
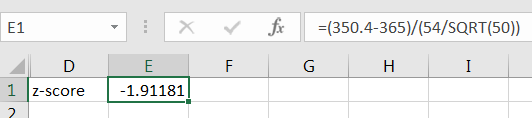
Recall that we can use Microsoft’s Excel to compute areas under normal distributions using the command , as shown in Figure 10.7.

Thus, the -value is approximately 0.0280. Since we would reject and conclude that there is significant evidence that the company is guilty of fraud.
Using to Compute a -value
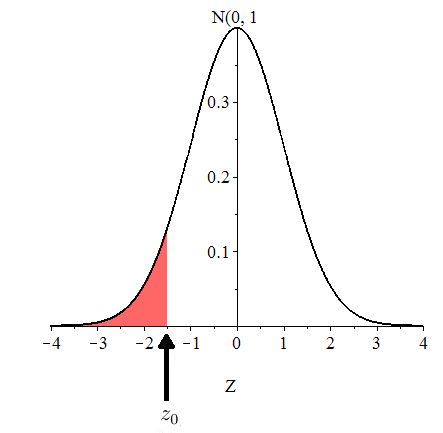
Note that in the calculations above, it wasn’t necessary to compute the test statistic to find the -value. But, in modern scholarly work, it is still commonly expected that the value of the test statistic be reported together with the found -value. The test statistic in Equation (10.3) can be used to compute the corresponding -value, which we will demonstrate now.
The -value is the chance of observing or anything more extreme (smaller), assuming is true ( That is, the -value is
as shown in Figure 10.9.
The calculation in Excel is given in Figure 10.10.
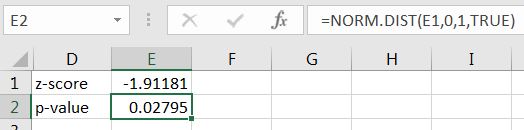
So, the same -value is gotten, and is rejected. Here’s how the result might be presented in a scientific journal: There is significant evidence ( ) that the average time for the product to break is less than 1 year.
Concepts Check: 1. Suppose that in a -Test, the -value is found to be 0.0558. If what is the conclusion of the test? Answer: Fail to reject 2. Suppose that in a -Test, the value of obtained is If the direction of extreme is to the left, as a probability, describe the corresponding -value. Answer: The -value is the probability of observing or anything smaller, assuming is true. 3. Suppose that in a -Test, the value of obtained is If the direction of extreme is to the left, as an area under a curve, describe the corresponding -value? Answer: The -value is the area under to the left of 4. Suppose that in a -Test, the value of obtained is If the direction of extreme is to the left, what Excel command will compute the corresponding -value? Answer: 5. Suppose the in a -Test, is the claim that and the summary statistics for the sample are and What is the value of the test statistic? Answer:
If the direction of extreme is to the right, the calculations are handled identically as given previously, except that -values are areas to the right. The subtlety here is that the Excel command gives area to the left, which we must remember so that a correct -value is computed.
Example 10.4.2.
A pet food manufacturer claims that each can of cat food they make contains 6 ounces of product. The manufacturer is concerned that the cans are being overfilled, so the company randomly selects 25 cans and measures the contents. The sample average and sample standard deviation for the sample are 6.20 and 0.51 ounces, respectively. At a level of 5%. test whether there is significant evidence that the cans are, on average, being overfilled. It is reasonable to assume that the population of ounces of food in cans is normal, and for reasons unknown, the population standard deviation is known to be
Solution: From Example 10.3.2 on page 10.3.2, the null hypotheses is and the direction of extreme to the right. Since the population is normal and is known, we can use a -Test. Since we need to compute a -score anyhow, we will consistently use the -score to compute the -value.
The -score for the observed sample mean is
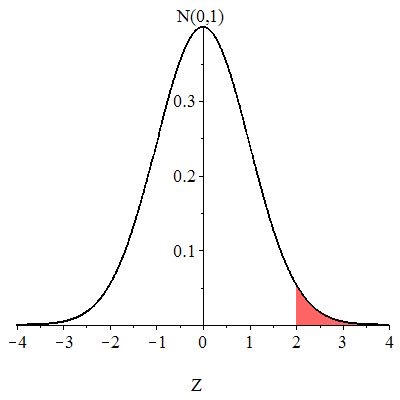
The -value is the chance of observing or anything more extreme (larger), assuming is true ( That is, the -value is
as shown in Figure 10.9.
The calculation in Excel is given in Figure 10.12.
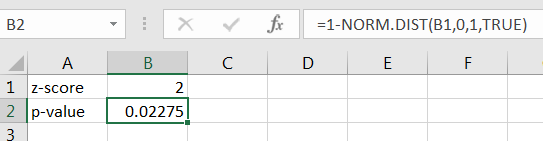
Since the -value is we reject That is, there is significant evidence ( ) that the true average amount of food in the cans is greater than 6 ounces.
If the direction of extreme is two-sided, then is of the form In this case, sample means that are larger or smaller than give evidence against Equivalently values of larger or smaller than 0 provide evidence against So to compute a corresponding -value, we compute area of the tail more extreme than and the area of the tail more extreme than the symmetric value of More precisely, under the curve the -value is the combined area to the right of and to the left of Figure 10.13 illustrates.
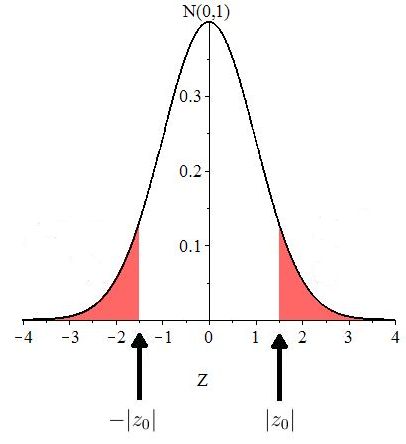
Example 10.4.3.
Let’s use the sample summary data from Example 10.4.2 on page 10.4.2, but use a two-sided direction of extreme. That is, suppose the competing hypotheses are:
For purposes of illustration, let’s perform the hypothesis test using
Solution: The calculation of the test statistic is unchanged, i.e., the test statistic is still
Since the direction of extreme is two-sided, however, the -value is the chance of observing or anything larger, together with the chance of observing or anything smaller, assuming is true. The -value is illustrated in Figure 10.14.
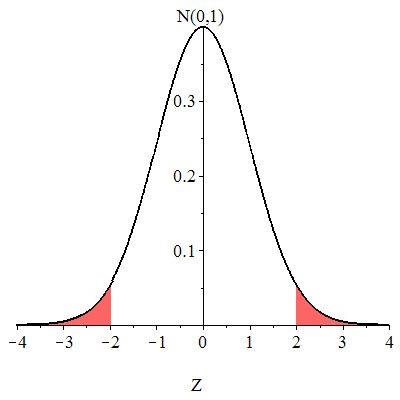
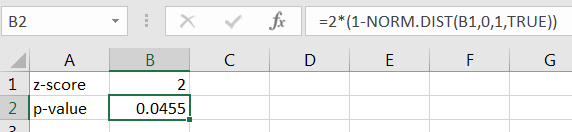
The calculation in Figure 10.15 computes the area to the right of then using the symmetry of the standard normal distribution multiplies the result by 2.
Since the -value is greater than we fail to reject Thus, there is insufficient evidence ( ) that the true mean amount of food in the cans is different than 6 ounces.
Exercises
-
1.
A psychologist is studying the distribution of IQ scores of girls at an alternative school. They want to test the hypothesis that the average IQ score is higher than 105. A random sample of 34 girls is taken and their sample average score was 106 with a sample standard deviation of 14. It is known that the population standard deviation is 15.
-
(a)
What is the population of interest?
-
(b)
State the competing hypotheses.
-
(c)
What is the direction of extreme?
-
(d)
Why is it reasonable to use a -Test?
-
(e)
Compute the test statistic and corresponding -value.
-
(f)
Sketch the -value.
-
(g)
State your conclusion at the level.
-
(h)
State the conclusion in a manner appropriate for a scientific journal.
-
(i)
What type of error could have been made?
-
(a)
-
2.
Colleges frequently provide estimates of student expenses such as housing. A local community college claims that the average student housing expense per month is $650. To test the claim, a consultant is hired. The consultant samples 200 students yielding a sample mean of $611.63 and sample standard deviation $132.85. It is known that the population standard deviation is $130.0.
-
(a)
What is the population of interest?
-
(b)
State the competing hypotheses.
-
(c)
What is the direction of extreme?
-
(d)
Why is it reasonable to use a -Test?
-
(e)
Compute the test statistic and corresponding -value.
-
(f)
Sketch the -value.
-
(g)
State your conclusion at the 5% significance level.
-
(h)
State the conclusion in a manner appropriate for a scientific journal.
-
(i)
What type of error could have been made?
-
(a)
-
3.
A company’s service technicians took an average of 1.8 hours to respond to trouble calls from business customers who had purchased service contracts. The CEO of the company believes that the average response time this year has decreased. A simple random sample size of 35 of independent response times from business customers is selected, yielding a sample mean and sample standard deviation of of 1.5 hours and 0.5 hours, respectively. It is known that the population standard deviation is 0.52 hours.
-
(a)
What is the population of interest?
-
(b)
State the competing hypotheses.
-
(c)
What is the direction of extreme?
-
(d)
Why is it reasonable to use a -Test?
-
(e)
Compute the test statistic and corresponding -value.
-
(f)
Sketch the -value.
-
(g)
State your conclusion at the level.
-
(h)
State the conclusion in a manner appropriate for a scientific journal.
-
(i)
What type of error could have been made?
-
(a)
-
4.
The Survey of Study Habits and Attitudes (SSHA) is a psychological test that measures the motivations, attitude toward school, and study habits of students. Scores range from 0 to 200. The mean score for U.S. college students is about 115. A teacher who suspects that older students have better attitudes toward school gives the SSHA to 25 students who are at least 30 years of age. Their sample mean score is 133.2, with sample standard deviation 32.0. It is known that the population of scores for students at least 30 years of age is normally distributed and that the population standard deviation is 35.
-
(a)
What is the population of interest?
-
(b)
State the competing hypotheses.
-
(c)
What is the direction of extreme?
-
(d)
Why is it reasonable to use a -Test?
-
(e)
Compute the test statistic and corresponding -value.
-
(f)
Sketch the -value.
-
(g)
State your conclusion at the level.
-
(h)
State the conclusion in a manner appropriate for a scientific journal.
-
(i)
What type of error could have been made?
-
(a)
-
5.
The average yield of corn in the U.S. is about 135 bushels per acre (BPA). A survey of 25 farmers this year gives a sample mean yield of 138.4 BPA and sample standard deviation yield of 15.1 BPA. We want to know whether this is good evidence that the national mean this year is not 135 bushels per acre. Assume that the farmers surveyed are a simple random sample from the population of all commercial corn growers, and that the population of bushels per acre is normally distributed. It is known that the population standard deviation is 15.0 BPA.
-
(a)
What is the population of interest?
-
(b)
State the competing hypotheses.
-
(c)
What is the direction of extreme?
-
(d)
Why is it reasonable to use a -Test?
-
(e)
Compute the test statistic and corresponding -value.
-
(f)
Sketch the -value.
-
(g)
State your conclusion at the 10% level.
-
(h)
State the conclusion in a manner appropriate for a scientific journal.
-
(i)
What type of error could have been made?
-
(a)
10.4.2 Decision Rules and Critical Values
Recall that a decision rule is a description of the values for either or for which a null hypothesis will be rejected. The collection of these values is called a rejection region. A value of or that delineates between rejecting and failing to reject is called a critical value.
These terms don’t add anything new structurally to hypothesis testing, but they are terms used by some scientists. Hence, we should be familiar with their meanings.
Case: Direction of Extreme to the Left
Suppose that is the claim that Note that the direction of extreme is to the left. Suppose that the significance level is given. In order to reject we would need that the observed -value is so the largest possible -value that still results in rejecting is if the -value is equal to Let denote the value of that gives a -value equal to i.e.,
This is shown in Figure 10.16.
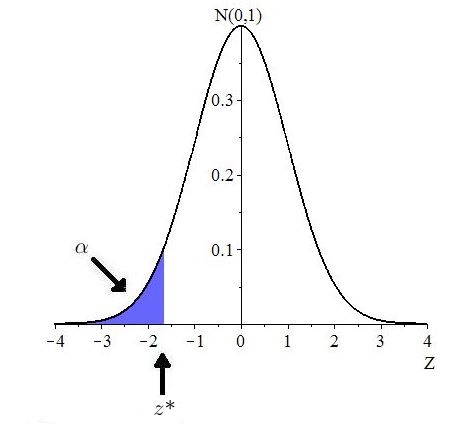
For an observed is rejected if and only because the -value is if and only if This interval, is called the rejection region. Figure 10.17 illustrates.
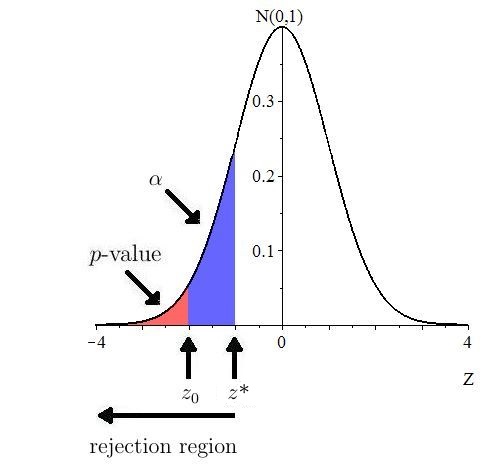
We can use the Excel command to compute For example, if then as shown in Figure 10.18.
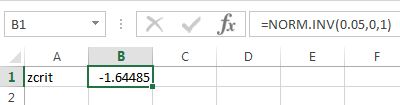
If is known, then Equation (10.3) can used to compute the critical value, for
| (10.4) |
The critical value works similarly, i.e., is rejected if and only if the observed sample mean is less than or equal to
Example 10.4.4.
Suppose that and Suppose a random sample of size yields a sample mean of 3.9, and suppose it is known that Use to decide on whether to reject
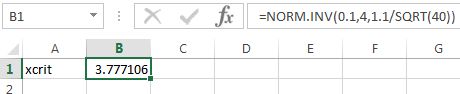
Solution: Using Excel, we have Equation (10.4) gives
and hence, Since the direction of extreme is to the left, the rejection region is all real numbers less than or equal to 3.78. The observed sample mean of 3.9 falls outside of the rejection region, so we fail to reject
Remark: In Example 10.4.4, can be found directly using , as shown in Figure 10.19. Note that computation uses the assumption that the is true in similar fashion to computing a -value, i.e., is used for the population mean and for the standard deviation.
Case: Direction of Extreme to the Right
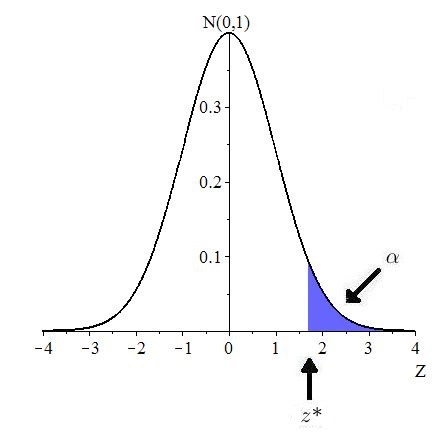
The only change here is that the direction of extreme switches the inequalities. For example, if the direction of extreme is to the right, then is chosen so that
Figure 10.20 illustrates.
For example, suppose and the direction of extreme is to the right. Then
as illustrated in Figure 10.21.
Case: Two-sided Direction of Extreme
If the direction of extreme is two-sided, then in order to determine the value of the significance level is split in half over the two tales. This is shown in Figure 10.22.
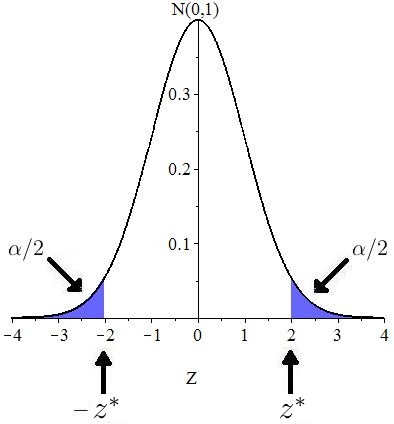
Example 10.4.5.
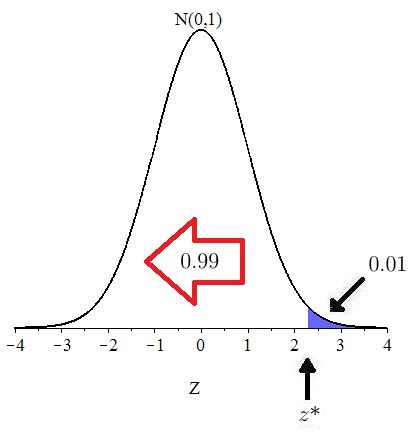
Suppose the direction of extreme is two-sided and that Compute
Solution: The area in each tail is so the area to the left of is as shown in Figure 10.23.
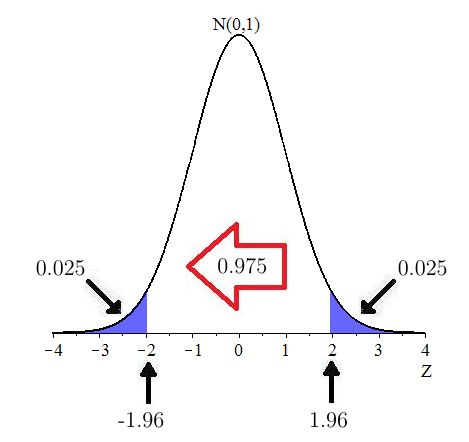
Using Excel, the value of can be computed using as follows:
In the Concepts Check below, assume that has been determined appropriate to use a -Test.
Exercises
-
1.
A psychologist is studying the distribution of IQ scores of girls at an alternative school. They want to test the hypothesis that the average IQ score is higher than 105. A random sample of 34 girls is taken and their average score was 106 with a standard deviation of 14. Use and and assume
-
(a)
What is the value of
-
(b)
In terms of what is the decision rule?
-
(c)
What is the rejection region?
-
(d)
What is the relationship between the decision rule and the rejection region?
-
(a)
-
2.
Colleges frequently provide estimates of student expenses such as housing. A local community college claims that the average student housing expense per month is $650. To test the claim, a consultant is hired. The consultant samples 200 students yielding a sample mean of $611.63 and sample standard deviation $132.85. Use and assume
-
(a)
What is the approximate value of
-
(b)
In terms of what is the decision rule?
-
(c)
Using part (b) and the observed sample mean, what is the decision made?
-
(a)
-
3.
A company’s service technicians took an average of 1.8 hours to respond to trouble calls from business customers who had purchased service contracts. The CEO of the company believes that the average response time this year has decreased. A simple random sample size of 35 of independent response times from business customers is selected, yielding a sample mean and sample standard deviation of of 1.5 hours and 0.5 hours, respectively. Use and assume
-
(a)
What is the value of
-
(b)
In terms of what is the decision rule?
-
(c)
Using part (b) and the observed sample mean, what is the decision made?
-
(a)
-
4.
The Survey of Study Habits and Attitudes (SSHA) is a psychological test that measures the motivations, attitude toward school, and study habits of students. Scores range from 0 to 200. The mean score for U.S. college students is about 115. A teacher who suspects that older students have better attitudes toward school gives the SSHA to 30 students who are at least 25 years of age. Their sample mean score is 133.2, with sample standard deviation 32.0. Use and assume
-
(a)
What is the approximate value of
-
(b)
In terms of what is the decision rule?
-
(c)
Using part (b) and the observed sample mean, what is the decision made?
-
(a)